
You initiate a script, ready to gather critical data. Everything runs smoothly for the first hundred requests. Then, it happens. The dreaded “I am not a robot” checkbox appears. Your operation halts. The server has flagged your request, and your access is blocked.
CAPTCHAs are more than just annoying images of traffic lights or crosswalks; they are significant roadblocks that disrupt automated workflows.
However, these challenges are rarely random. They act as a penalty for suspicious activity rather than a default gate. By understanding how these defense mechanisms work, you can deploy strategies to overcome them.
This guide explores web scraping captcha handling, focusing on how Decodo provides a robust solution through advanced anti-detection and automated solving.
Why Websites Show CAPTCHAs during Automation Attempts

Before fixing the problem, you must understand the trigger. Security systems like Google’s reCAPTCHA or hCaptcha exist to distinguish human users from automated bots. They do not just appear randomly; they appear when a website’s security layer detects anomalies.
Common triggers include:
ReCAPTCHA v3, for instance, is invisible. It assigns a score from 0.0 (bot) to 1.0 (human) based on browser fingerprinting captcha analysis and IP reputation. If your score drops too low, the site serves a challenge. Therefore, web scraping captcha handling starts with maintaining a high trust score.
Stop CAPTCHAs Before they Start with Smart Avoidance
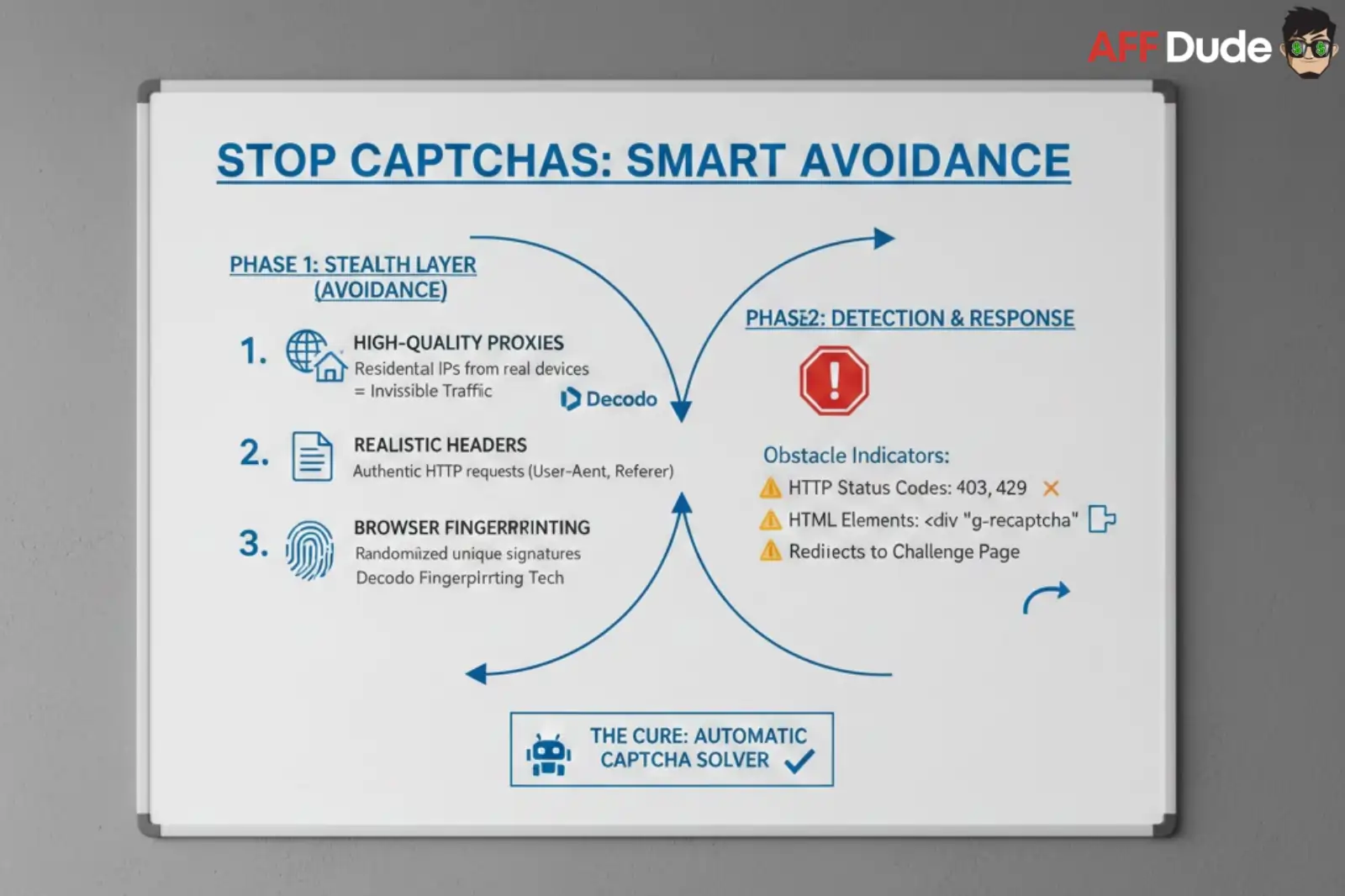
The most efficient way to handle a CAPTCHA is to never trigger one in the first place. Scrape without captcha interruptions by prioritizing avoidance. This requires a “Stealth Layer” in your code.
Phase 1: The Stealth Layer (Avoidance)
To keep your operations invisible, you must mimic organic human traffic.
Phase 2: Detection and Response
Even with the best stealth, challenges can occur. Your script must know when it has been caught. Simply crashing is not an option.
You need to programmatically detect obstacles. Common indicators include:
Once detected, the “Cure” phase begins. This is where an automatic captcha solver becomes essential.
Decodo: The Automated Captcha Bypass Solution

Manual intervention kills automation. You cannot sit and solve puzzles for a script running thousands of requests per hour. This is where Decodo shines. It serves as an all-in-one web scraping API that handles the heavy lifting.
Unlike basic tools that just rotate IPs, Decodo integrates advanced CAPTCHA solving techniques directly into the request pipeline.
How Decodo Solves on the Fly
When you route your requests through Decodo, the process is seamless:
While external manual solving services can delay scraping by 10-30 seconds per request, Decodo’s internal handling drastically reduces latency. Combined with intelligent rotation, Decodo maintains a success rate of 99%+.
Switching From Basic Requests To Decodo API
Let’s look at how you can switch from a fragile local script to a robust, Decodo-powered solution.
Standard Python Request (Vulnerable)
import requests
# This request is likely to fail on protected sites
url = "https://example-protected-site.com"
headers = {"User-Agent": "Mozilla/5.0"}
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
print("Success")
else:
print(f"Blocked: {response.status_code}")
except Exception as e:
print(f"Error: {e}")The Decodo Approach (Secure)
By using Decodo, you gain access to scraping google without captcha issues. You simply route your request through the API, and the sophisticated rotation and solving happen in the background.
import requests
# Decodo API configuration
api_key = "YOUR_DECODO_API_KEY"
target_url = "https://example-protected-site.com"
# Constructing the API request
payload = {
"url": target_url,
"render": True, # Useful for JS-heavy sites
"country": "us" # Geo-targeting with residential IPs
}
headers = {
"Authorization": f"Bearer {api_key}"
}
# Sending the request to Decodo
response = requests.post("https://api.decodo.io/v1/scrape", json=payload, headers=headers)
if response.status_code == 200:
data = response.json()
print("Content retrieved successfully!")
# Proceed to parse HTML
else:
print("Error retrieving data")In this example, Decodo manages the anti-bot challenge solution. If a CAPTCHA appears, the API solves it before sending back the 200 OK status and the content.
Essential Strategies For Long Term Scraping Success
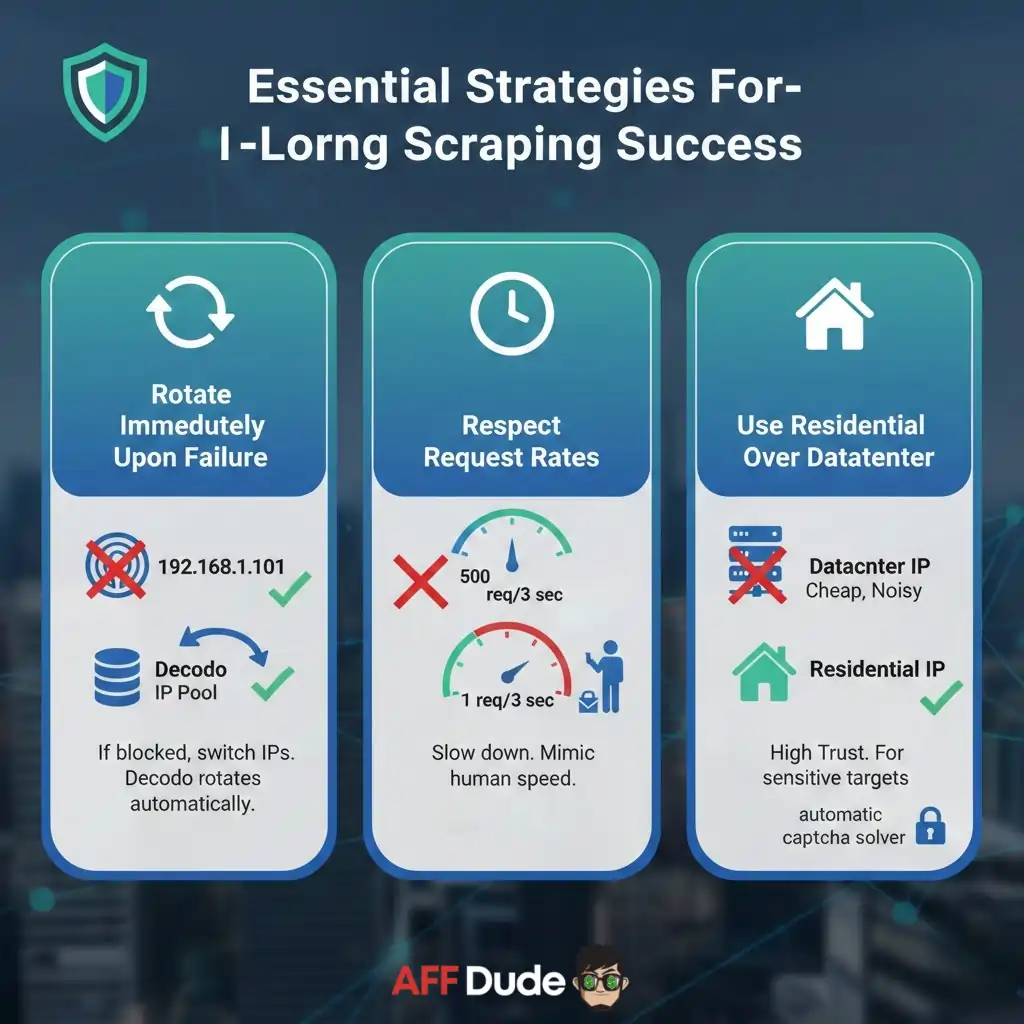
Even with powerful tools, maintaining a low profile ensures long-term success.
Keep Your Web Scraper Running Without CAPTCHA Hassles
CAPTCHAs function as speed bumps, not impenetrable walls. They exist to filter out low-quality, unsophisticated traffic.
By upgrading your infrastructure to use high-quality residential IPs and realistic browser fingerprinting, you stop looking like a bot.
When challenges do arise, you need a system that reacts instantly. Decodo provides that reliability. By combining a vast residential IP network with automated captcha bypass technology, it ensures your data pipeline remains uninterrupted.
Stop fighting with “I am not a robot” checkboxes. Equip your scraper with the right tools and focus on the data, not the defenses.
Recommended Articles




